写在最前:问题咨询请直接点击此处提交 ISSUE
- ⭐️ 请先 Star 本项目后再提问,作者精力有限,未 Star 直接 Close
- 🐞 GitHub ISSUE 需包含:问题截图 + SDK版本 + 配置代码
快速上手
本文章将带领大家从零开始构建一个基础 RAG 系统。通过白盒编码的方式,不仅能深入理解 RAG 的核心原理,还可以根据实际需求灵活调整和优化各个环节。相比直接使用现有的开源 RAG 产品,这种方式能让我们更好地掌控系统行为,实现更精准的知识检索和问答效果。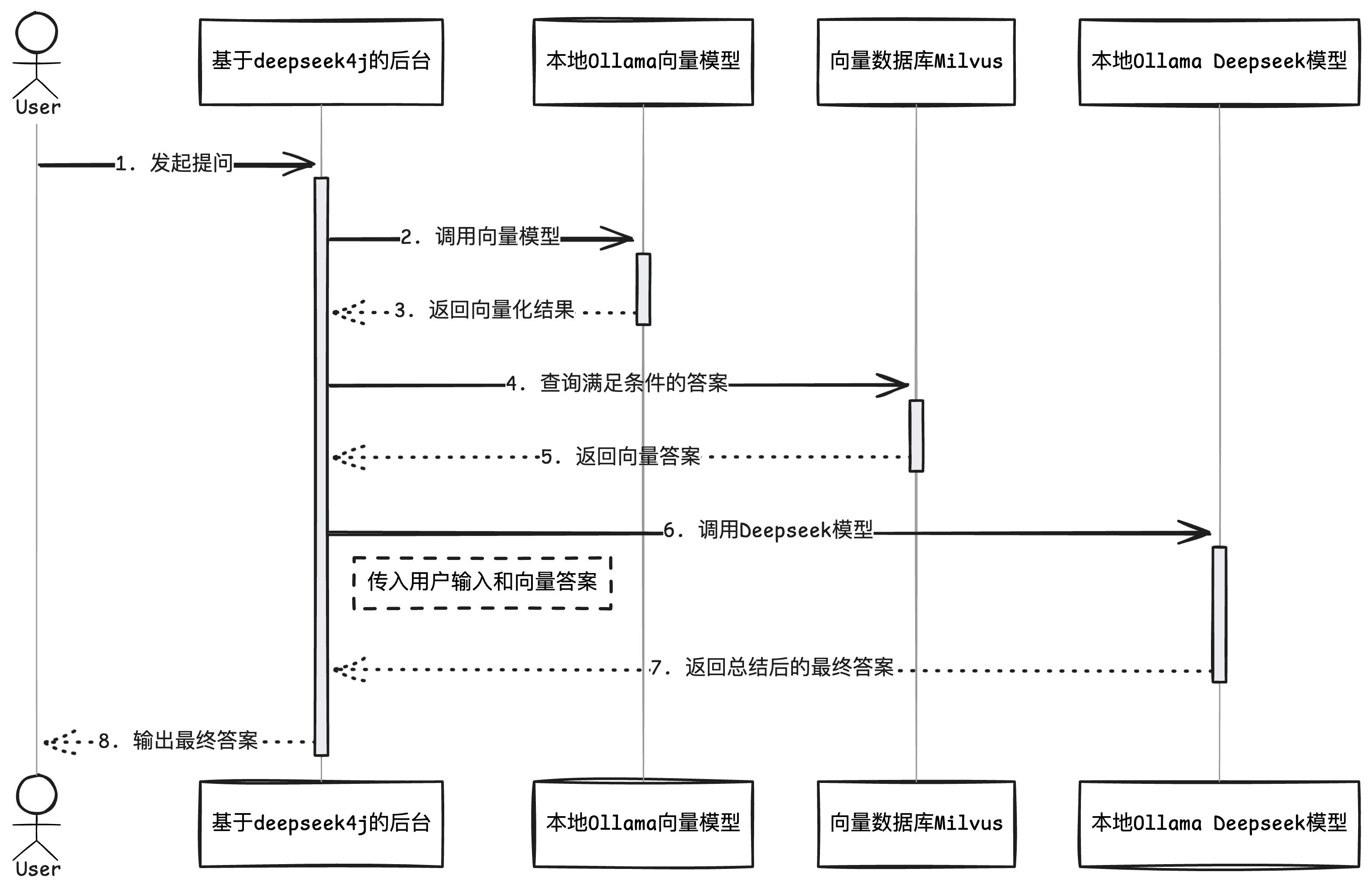
1. 环境准备
在开始构建 RAG 系统之前,我们需要准备以下环境:1.1 Ollama 模型准备
首先安装 Ollama,然后下载以下必要的模型:1.2 向量数据库准备
本文使用 Milvus 作为向量数据库,你可以选择以下两种方式之一进行安装: 方式一:使用milvus 测试环境- 访问 Zilliz Cloud 中文版:https://cloud.zilliz.com.cn
- 获取连接信息(后续配置需要用到)
注意:如果选择 Docker 安装方式,请确保你的网络环境能够正常访问 Github。
- 初始化向量数据:创建本次知识库存储、获取链接信息和表信息:
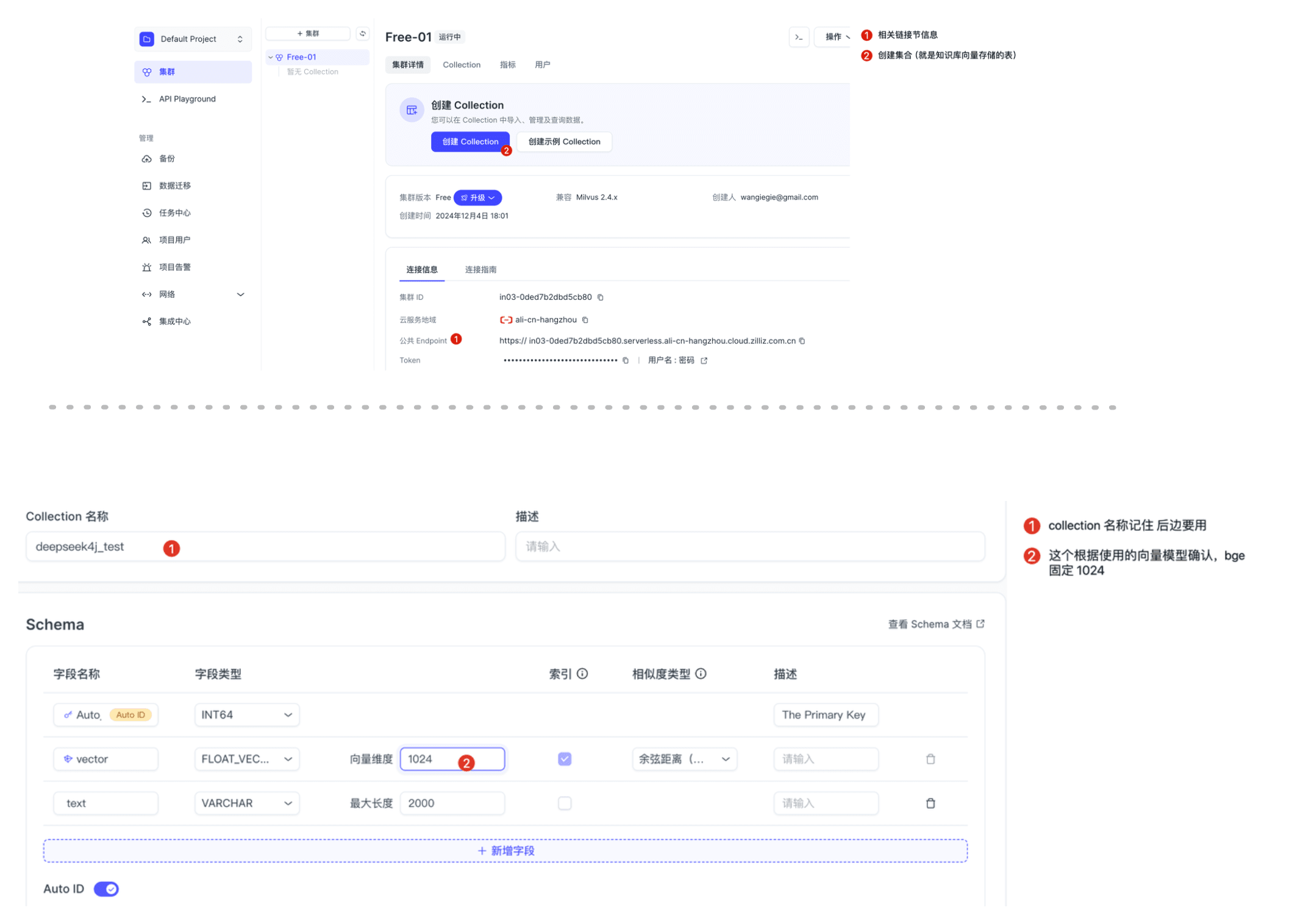
1.3 项目依赖
在你的 Maven 项目中添加以下依赖:application.yml 配置
2. 初始化私有知识
在构建 RAG 系统时,第一步是将已有的知识内容转换为向量形式并存储到向量数据库中。2.1 创建链接 链接客户端
2.2 准备资料并向量化上传
以下示例演示如何处理文本资料。对于 Office 文档、图片、PDF、音视频等其他格式的文件处理,deepseek4j 提供了完整的解决方案,详细使用方法请参考官方文档: https://javaai.pig4cloud.com/deepseek。3. 创建 RAG 接口
前端测试
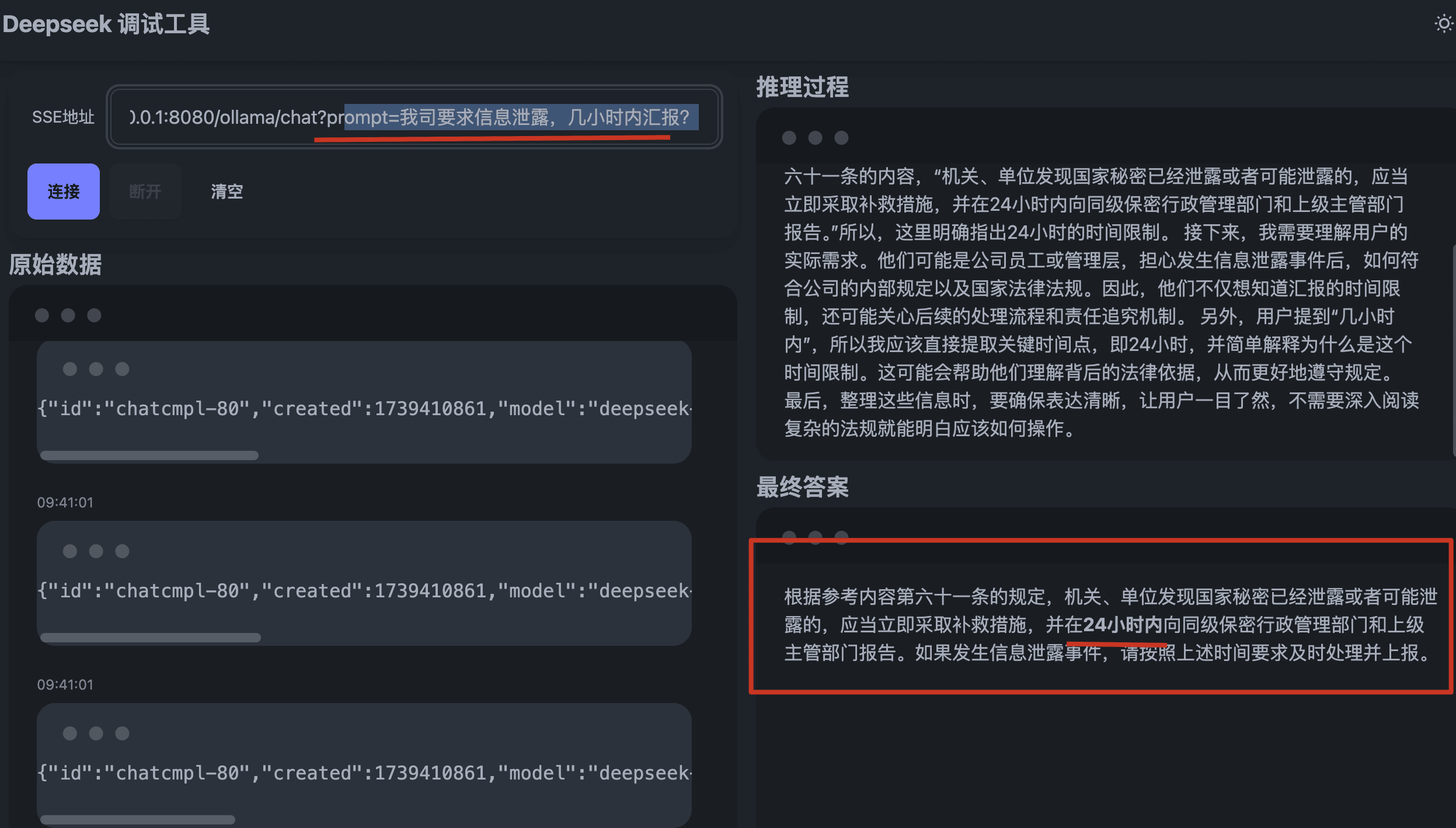
总结
本文通过以下核心步骤快速构建了基础 RAG 系统:- 环境准备:部署推理模型和向量模型
- 知识库构建:向量化存储
- 检索增强:通过语义搜索获取关联知识
- 推理生成:结合上下文生成最终回答
- 检索策略优化:结合关键词和语义的混合检索,提高召回准确度
- 重排序优化:对检索结果进行二次排序,确保最相关内容排在前面
- 提示词工程:优化 Prompt 模板,引导模型生成更准确的回答
- 知识库管理:定期更新和维护知识库,保证数据时效性
- 性能调优:优化向量检索和模型推理的性能
商业化选择
PIG AI应用开发平台 | 适合中大型企业构建自主可控的AI中台
为Java开发者提供全栈式AI工程化解决方案,强类型/高可维护性架构,内置30+主流大模型支持。
- 🔍 知识引擎体系:RAG 知识引擎全自动化多模态解决方案
- 📝 AI-OCR 中枢:复杂非标场景高精度识别
- ⚙️ 业务智能融合:函数编排 + Chat2SQL,无缝对接现有业务系统
- 🛡️ N维风控体系:敏感词/IP/Token/User 规则控制引擎
文档有误?请协助编辑
发现文档问题?点击此处直接在 GitHub 上编辑并提交 PR,帮助我们改进文档!
文档有误?请协助编辑
发现文档问题?点击此处直接在 GitHub 上编辑并提交 PR,帮助我们改进文档!